Big data jsou víc než jen petabajty. Jejich zpracovávání je příležitost i hrozba
Velký objem dat nemusí automaticky znamenat, že se jedná o big data. Ta jsou totiž charakteristická hned několika proměnlivými vlastnostmi. V jednom se ale neliší – jejich zpracování je náročné a komplikované. I přesto se do jejich zpracování v mnoha případech vyplatí investovat. Jak práce s big daty funguje a jaká je jejich odvrácená strana?
JAN MŮČKA
16. 12. 2020
8 min čtení
Ve věku informatiky jsou data a jejich zpracování klíčem k úspěchu. Bez nejrůznějších analýz by dnes už velká část firem a organizací vůbec nemohla fungovat. Způsobů, jak vytáhnout z nejrůznějších typů dat užitečnou informaci, je mnoho. Někdy ještě stále postačí zkušené oko manažera, jindy je potřeba využít počítače nebo servery. Co když je ale dat tolik a jsou v takové podobě, že už je nelze běžnými způsoby zpracovat?
Právě v takové chvíli se jedná o problematiku velkých dat, pro které se i v Česku spíše používá anglický výraz big data. Práce s takovými daty je často komplikovaná a vyžaduje speciální software a server nebo cloud s vysokým výpočetním výkonem.
Zpracovávejte big data v AWS
Přenášejte informace ze svých serverů uložených v datacentrech MasterDC do AWS bezpečně a s nízkou latencí. Díky službě AWS Direct Connect můžete snadno přenášet informace do obřích datových skladů nebo využívat specializované big data platformy od Amazonu.
Hranice, kdy už lze datový soubor označit za big data je velmi tenká a proměnlivá. Neváže se jen na velikost dat, ale hned na několik charakteristik, které bývají označovány jako 4V podle svých anglických názvů – volume, velocity, variety a veracity. Některé zdroje uvádí až 7V, když dodávají ještě value, variability a visualisation.
Charakteristika big dat
Velikost (volume) – Vyjadřuje objem všech zpracovávaných dat. Minimální velikost, od které lze hovořit o big datech, není pevně stanovena. Řádově se ale většinou jedná o vyšší desítky TB až PB.
Rychlost (velocity) – V mnoha případech big data kontinuálně přibývají, mezi jejich základní vlastnosti proto patří rychlost generování a zpracování dat. Na rozdíl od minulosti je už dnes běžné, že se vše děje téměř v reálném čase.
Různorodost (variety) – Právě různorodost způsobuje při práci s big daty nezřídka největší problémy. Data totiž bývají strukturovaná i nestrukturovaná a mohou mít různou podobu – od databáze přes příspěvky na Facebooku až po videa.
Důvěryhodnost (veracity) – Aby bylo možné výstup správně interpretovat, je nutné vědět, jak moc jsou vstupní data důvěryhodná. To samozřejmě úzce souvisí s tím, z jakého zdroje pochází.
Hodnota (value) – Práce s big daty stojí mnoho času i peněz a výsledek by proto měl být adekvátní vynaloženým zdrojům. Například analýzou záznamů z videokamer složitě zjišťovat, že 78 % zákazníků supermarketu nemělo čepici, nebude mít asi příliš velkou hodnotu.
Proměnlivost (variability) – Sbírat opakovaně data, u nichž se nic nemění, nedává smysl. Například informace, že dnes vyšlo slunce, bude vždy stejná. Měnit se však bude čas, kdy vyšlo, a jak dlouho trvalo, než zase zapadlo.
Vizualizace (visualization) – Možnost převést big data a výsledky jejich zpracování do různých grafů a diagramů zjednodušuje interpretaci a často tak lze mnohem rychleji odhalit zajímavé vztahy a korelace než z psaných reportů a tabulek. Ne všechna data je ale možné rozumně vizualizovat.
Odkud se big data berou?
Zdroj big dat souvisí především s cílem výzkumného snažení. Pokud chceme například analyzovat chování potenciálních zákazníků, což je velmi častý cíl při zpracování big dat, mohou být zdrojem příspěvky na nejrůznějších sociálních sítích nebo třeba data o uživatelském používání e-shopů.
Jen pro zajímavost, každou minutu přibývají na Twitteru i Facebooku řádově stovky tisíc příspěvků, na Youtube se nahrají stovky hodin videí a na Instagramu uživatelé zveřejní desetitisíce nových fotek. To je za 60 vteřin opravdu pořádná nálož dat, kterou lze z nejrůznějších úhlů analyzovat.
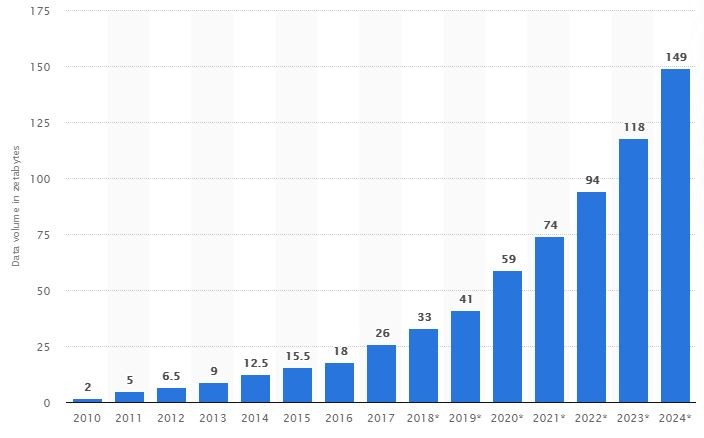
Podle odhadů z webu Statista se v roce 2020 pohyboval celkový objem dat na světě okolo 59 ZB, což je pro „lepší představu“ 59 miliard TB. Podle predikce, kterou si lze prohlédnout v grafu níže, by se navíc v roce 2023 měla velikost dat zhruba zdvojnásobit.
Objem dat na internetu v ZB a predikce nárůstu do roku 2024. Zdroj: statista.com
Zpracování big dat
Aby bylo možné big data analyzovat, je potřeba je nejprve posbírat a někam uložit. K tomu se využívají specializované relační databáze, tzv. datové sklady, které umožňují následné analýzy těchto dat. Ještě před samotnou analýzou je ale nutné data vhodně uspořádat a provést jejich čištění.
K samotným analýzám se v závislosti na typu dat a požadovaném výstupu využívá velké množství různých přístupů, platforem a nástrojů. Dobrou zprávou je, že s technologickým pokrokem jsou možnosti, jak big data zpracovávat, stále dostupnější a přestávají tak být výsadou těch největších korporací, vědeckých institucí a vlád.
Velký podíl na zlevnění má zcela jistě i rozvoj cloud computingu. Například technologie AWS Direct Connect umožňuje vysokorychlostní odesílání dat ze serverů uložených u lokálního poskytovatele do obřích datových center Amazonu, kde lze big data zpracovávat v rozumném čase. Amazon navíc nabízí mnoho různých platforem, které jsou právě na zpracování big dat zaměřené, jako třeba Amazon EMR, Amazon Redshift nebo Amazon Kinesis.
Kdo big data využívá?
Zpracovaná big data poskytují velmi přesné a komplexní informace, které se dají použít k nejrůznějším účelům. Ve velkém je využívají vlády, různě velké podniky, banky nebo třeba vědci. Představme si proto několik konkrétních případů jejich využití:
Byznys a finančnictví
Přidanou hodnotu vytěženou z analýzy big dat dává svým zákazníkům realitní kancelář Windermere Real Estate. Ta zpracovává údaje od desítek milionů řidičů v okolí konkrétního domu, aby kupujícím poskytla údaje o dopravě v okolí. Známá malobchodní společnost Walmart zase zpracuje přes milion zákaznických transakcích za hodinu a podle odhadů skladuje přibližně 2,5 PB dat.
Velká data jsou také ve velkém analyzována na burzovních trzích, kde každou vteřinu přibývají nové informace, které je navíc možné analyzovat mnoha způsoby a nástroji. Vytěžené informace pak slouží brokerům a velkým investičním společnostem k tomu, aby přesněji odhadovali pohyb světových trhů.
V neposlední řadě se big data využívají k zajištění bezpečnosti díky analýzám, založených na uživatelském chování. Například některé banky sbírají biometrické údaje svých zákazníků, aby dokázaly odhadnout, jestli se jedná o skutečného majitele účtu. Analyzují proto třeba obvyklé chování v internetovém bankovnictví, rychlost psaní, pauzy mezi údery do klávesnice nebo informace o práci s myší.
Věda
Zpracování big dat významně usnadňuje vědecké poznání. Například dekódování lidského genomu, které by běžně trvalo 10 let, lze nyní zvládnout za jediný den. NASA zase využívá superpočítačový cluster Discovery, kde ukládá kolem 32 PB dat z pozorování a simulací klimatu.
Cambridge Analytica
Společnost Cambridge Analytica se zabývala zejména politickým marketingem. Její metody však byly poměrně revoluční – díky spojení big dat a psychometrie dokázala v podstatě konstruovat digitální avatary jednotlivců a s velkou úspěšností odhadovat jejich chování. Díky účelné a agresivní marketingové komunikaci následně manipulovala s realitou lidí tak, aby spolehlivě ovlivnila jejich volební chování.
Cambridge Analytica takto nejspíše ovlivňovala mnoho důležitých voleb v Africe, referendum o vystoupení z EU ve Velké Británii a přispěla k překvapivému vítězství Donalda Trumpa v prezidentských volbách v roce 2016. Svou činnost společnost ukončila po skandálu v roce 2018, kdy vyšlo najevo, že ilegálně získala data z uživatelských profilů na Facebooku.
Čína
Čína využívá zpracování big dat ke sledování svých občanů, kdy z kamer snímá obličeje, které následně analyzuje. Technologie, kterou vláda používá, dokáže rozpoznat věk, pohlaví a podle informací Českého rozhlasu se testuje i identifikace rasy. Tato funkce je vyvíjena ve spolupráci s firmou Huawei a má mimo jiné pomoci šikaně ujgurské menšiny ze strany čínské vlády.
Podobným příkladem je i poměrně známý čínský systém Social Credit. Ten má na základě zpracování dat o společenských, ekonomických i digitálních aktivitách občanů udělovat různý přístup k veřejným službám, funkcím a vliv má i na možnost vycestovat. Poslušný občan naopak snáze získá hypotéku nebo půjčku a bude mít přístup k lepšímu vzdělání i zaměstnání. Získaný sociální kredit může mít dokonce vliv i na rychlost internetového připojení.
Reportáž francouzské mezinárodní televize France 24 o zaváděném systému Social Credit v Číně. Zdroj: Youtube.com
Big data a růžovo-černá budoucnost
Zpracování a využití big dat má jistě velkou budoucnost. Stačí se podívat na IT trendy a hned je zřejmé, že v nich budou hrát big data důležitou roli. Jako příklad lze uvést strojové učení, které je hojně využíváno nejen pro umělou inteligenci. Zpracování velkého množství dat bude alfou a omegou i při rozvoji rozšířené reality a notnou dávku dat určených k další analýze lze očekávat i ze samořiditelných aut nebo IoT čipů.
Jak ale ukazují i některé příklady ze současnosti, velká moc big dat s sebou nese i značné riziko zneužití. Automatické sledování a identifikace lidí, sociální kredit nebo párování nejrůznějších typů informací mohou být pouhým začátkem technologické diktatury. Určitou hranu etiky a někdy i legálnosti zakouší také novátorské přístupy k politickému i běžnému marketingu, které dokáží predikovat chování a cílit reklamu na úrovni jedince.
Na druhé straně může technologický pokrok ve zpracování big dat posunout lidskou společnost k netušeným možnostem. Díky stále větší dostupnosti budou navíc hrát big data důležitou roli v rozhodování firem. Na základě výsledků z vytěžených dat mohou optimalizovat nejen svůj marketing, ale třeba i produkt nebo samotný chod firmy.
Maximálně jednou měsíčně vám pošleme přehled toho nejlepšího, co u nás na blogu vyšlo.
Nastavení cookies
Pro správnou funkci webu využíváme cookies a osobní údaje. Některé jsou technicky nezbytné, jiné soubory a osobní údaje používáme k monitorování dění na webu a přizpůsobení reklam vašim preferencím. Podrobné informace nejdete tady.
Technické
Vždy aktivní
Technické cookies jsou nezbytné pro správné a bezpečné fungování internetových stránek a není možné je vypnout. Při jejich zakázání v prohlížeči nemusejí stránky následně fungovat správně.
Předvolby
Technické úložiště nebo přístup je nezbytný pro legitimní účel ukládání preferencí, které nejsou požadovány účastníkem nebo uživatelem.
Analytické
Analytické cookies a osobní údaje nám umožňují zaznamenávat aktivitu uživatelů na webu pomocí nástrojů třetích stran (např. Google Analytics). Tyto informace využíváme k uživatelské optimalizaci stránek.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketingové
Marketingové cookies a osobní údaje pomáhají zobrazovat a cílit reklamy v obsahových a vyhledávacích sítích (např. od společnosti Google či Facebook), které jsou pro konkrétního uživatele relevantní a odpovídají jeho profilu či zájmům.