Katastrofou, která postihne datacentrum, v němž běží váš projekt, nemusí být zrovna silné zemětřesení. Že taková živelní pohroma nemůže zasáhnout IT infrastrukturu v srdci Evropy, je nejspíš pravda. Událostí ohrožujících chod serverů a cloudů je ale nespočet. Vzpomeňte si na požár z 10. března letošního roku ve štrasburském datacentru společnosti OVHCloud. Neblahé následky mohou mít ale i rozsáhlé výpadky elektřiny nebo síťové konektivity či neúmyslné chybné konfigurace. I proto je lepší být připraven a vymyslet scénář pro krizovou situaci ve chvíli, kdy je na to dostatek prostoru a není potřeba jednat pod tlakem.
Takový scénář představuje disaster recovery – plán obsahující jasné pokyny, hierarchicky řazené úkoly a rozdělení rolí tak, aby došlo k systematickému překlenutí rozsáhlého výpadku, nasazení záložních zdrojů a navrácení systému do původního stavu v co nejkratším čase s co nejmenšími ztrátami.
Disaster recovery proto nemůže nahradit prostá záloha, která je bez efektivního obnovení a pravidelné kontroly konzistence k ničemu. Replikace dat zase nezahrnuje procesy postupného zapínání serverů a spouštění skriptů. Zastoupit ji bohužel nedokážou ani jiná opatření pro vysokou dostupnost, protože ta přistupují k datům jinak a pracují se selháním jednoho uzlu či komponenty infrastruktury, nikoli celého řešení. Velice často se setkáváme s tím, že jsou pojmy disaster recovery a vysoká dostupnost nesprávně spojovány.
4 zásadní kroky pro záchranu infrastruktury
Tvorbě disaster recovery musí předcházet detailní analýza firemního IT i veškerých rizik, která by jej mohla ohrožovat. Co bude firma potřebovat pro překlenutí výpadku, pomohou stanovit čtyři body níže, na které by se během analýzy nemělo zapomenout.
1. Spočítejte si, kolik by vás to stálo
Náklady na disaster recovery nebudou malé a v prvních chvílích se taková investice může zdát zbytečná. Jak by ale budoucnost firmy ovlivnilo, kdyby se ze dne na den ocitla bez dat? Takové ztráty v mnoha případech vysoce převyšují náklady na plán obnovy. Zaměřte se proto na všechna potenciální rizika a analyzujte jejich možné dopady.
2. Myslete na data i infrastrukturu
Technická část disaster recovery začíná přípravou infrastruktury ve druhé lokalitě. Nemluvíme jen o storage systémech a datech, ale o veškerých výpočetních kapacitách. Záložní lokalita by se navíc měla nacházet zcela odděleně od té primární, a to jak pozičně tak technicky (tzn. jiný dodavatel napájení, jiná konektivita, atp.).
3. Definujte přijatelný výpadek i datové ztráty
Stanovení cílového stavu dat (RPO) a tolerance pro maximální délku výpadku (RTO) bude dalším důležitým krokem při tvorbě plánu zotavení. Každý podnik má v tomto ohledu individuální nároky. Třeba pro populární e-shop s elektronikou by mohlo několik hodin nefunkčního webu znamenat velké ztráty, zatímco existenci místního stolařství takový stav pravděpodobně neohrozí.
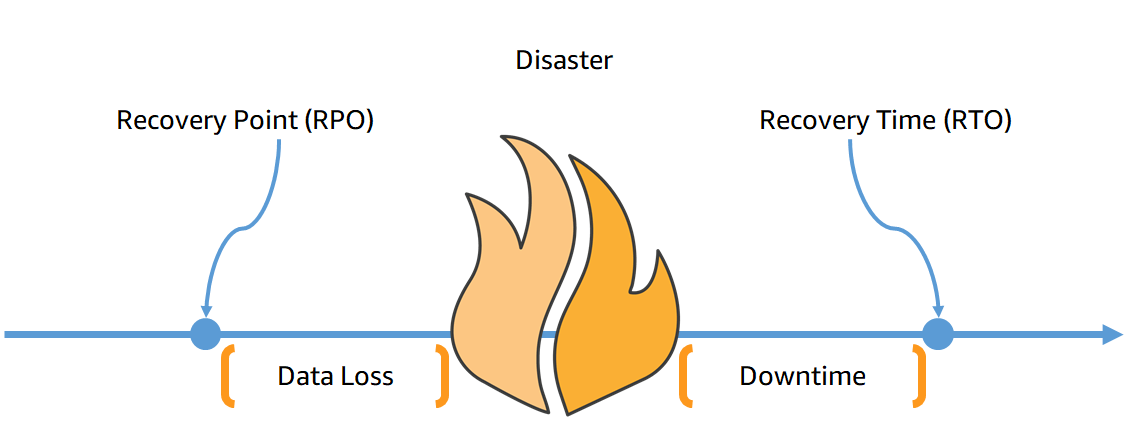
Schéma zobrazuje, kde se na časové ose nacházejí RPO a RTO. Zdroj: aws.amazon.com
4. Sestavte si inventář obnovy serverů i aplikací
Zvlášť u velkých projektů bude kompletní obnova nějakou dobu trvat. Bez některých operací a procesů se ale firma neobejde ani několik minut. K tomu slouží seznam priorit, podle kterého se při zotavování infrastruktury postupuje, aby byly zprovozněny nejprve ty aplikace, které jsou pro daný podnik kritické.
Technická realizace disaster recovery – architektura řešení
Z podrobné analýzy, kterou stručně shrnují čtyři body výše, už se dá vyvodit celkem slušná představa o tom, jak by měla struktura disaster recovery vypadat. Její finální podoba se samozřejmě nedá zobecnit. Pro lepší představu si ukážeme architekturu záložní infrastruktury alespoň na řešení, které jsme navrhli v MasterDC.
Schéma níže zobrazuje disaster recovery sestavenou ve virtuálním prostředí. Realizace v cloudu výrazně urychluje proces obnovy a umožňuje dosáhnout lepších hodnot RPO a RTO než ve fyzickém prostředí.
Virtualizační platformy nabízejí pro účely disaster recovery specializované nástroje, které dokážou spustit obnovu automatizovaně a testovat plány DR při běžném provozu bez vlivu na produkční prostředí.
Efektivní disaster recovery lze ale vytvořit i pro fyzické prostředí. V obou případech bude potřeba kvalitní replikační software, ideálně takový, který vás bude schopen dostat na požadovanou hodnotu RPO.
V MasterDC používáme softwarově definovaný Veeam Backup and Replication zajišťující automatickou tvorbu replik i monitoring. Nástroj umožňuje návrat nejen k poslední replice, ale i některé starší, pokud existuje. Počet uchovávaných replik a interval replikace závisí na potřebách každého projektu – i tady vycházíme z výsledků předchozí analýzy rizik, která mohou nastat.

Jak může vypadat architektura disaster recovery.
Testujte! Opravdu… hlavně před spuštěním
Promyslet veškerá rizika, investovat peníze a energii do přípravy celé infrastruktury a replikačních systémů by bylo k ničemu, kdyby se řešení před nasazením ostré produkce neotestovalo. Jen v praxi zjistíte, zda se na něco nezapomnělo nebo se někde nevloudila chybička, kvůli níž může být systém nefunkční.
Testování disaster recovery doporučujeme provádět ale i průběžně po nasazení, aby v případě selhání proběhlo vše hladce a nemuseli jste si dělat starosti s technickou stránkou věci. Disaster recovery plán totiž zdaleka není jen o IT infrastruktuře.
Vzkříšení IT nezajistí plynulý chod podnikání
Obnova IT by měla být součástí tzv. business continuity plánu zahrnujícího veškeré obchodní a distribuční procesy i další aspekty, které jsou zásadní pro celkový chod společnosti. Business continuity plán lze v podstatě rozdělit na tři zásadní části: IT infrastruktura, zaměstnanci a zákazníci.
Koordinace zaměstnanců a dobrá komunikace se zákazníkem je plně v režii firmy. Pro případ výpadku se hodí mít předem rozdělené úkoly a přidělit odpovědnost za konkrétní oblasti určitému zaměstnanci. Informace by měly proudit napříč společností kontinuálně a především konzistentně.
Prioritou je rovněž externí komunikace. Zákazník musí vědět, že máte vše pod kontrolou. Informujte ho srozumitelně o tom, co se děje a pokud ještě neznáte podrobnosti, hlaste se pravidelně s updaty o situaci.
Technickou část plánu, tedy disaster recovery, můžete přenechat schopnému poskytovateli řešení. Administrátoři a architekti z MasterDC analyzují firemní IT a navrhují záložní infrastruktury, přičemž účast zákazníka je v těchto procesech minimální. Stačí nadiktovat požadavky a zkonzultovat rizika a priority – zbytek už nemusíte řešit.

